Blog
·
How We Improved Terminal-Bench 2.0 Scores by Over 5x Using Tinker and Harbor

Spencer M.

Michael E.

AfterQuery researchers built a two-stage post-training pipeline using Tinker and Harbor. This pipeline was used to improve openai/gpt-oss-20b from 3.1% to 17.0% on Terminal-Bench 2.0, beating the performance of Gemini 2.5 Flash without training on a single task from the official eval set. Terminal-Bench 2.0 evaluates agent proficiency in terminal tasks spanning software engineering, system administration, and data processing.
103 | Terminus 2 | Grok 4 | xAI | 23.1% ± 2.9 |
106 | Terminus 2 | GPT-OSS-120B | OpenAI | 18.7% ± 2.7 |
— | Terminus 2 | AQ-GPT-OSS-20B (finetuned) | AfterQuery | 17.0% ± 2.5 ▲ |
108 | Terminus 2 | Gemini 2.5 Flash | 16.9% ± 2.4 | |
112 | Terminus 2 | Grok Code Fast 1 | xAI | 14.2% ± 2.5 |
117 | Terminus 2 | GPT-5-Nano | OpenAI | 7.9% ± 1.9 |
120 | Terminus 2 | GPT-OSS-20B | OpenAI | 3.1% ± 1.5 |
Scores sourced from the official Terminal-Bench 2.0 leaderboard.
The pipeline
Our training pipeline had two sequential stages. The first stage teaches the model what good terminal-agent behavior looks like via SFT on gold trajectories. The second stage uses RL to push the model toward solving harder problems it only partially gets right after SFT.
Stage 1: Supervised Fine-Tuning
We fine-tune on successful terminal-agent trajectories (explore → plan → edit → test → debug → pass), with zero overlap with the Terminal-Bench 2.0 eval set.
SFT is built into the Tinker SDK. A single CLI call handles GPU allocation and training:
terminal
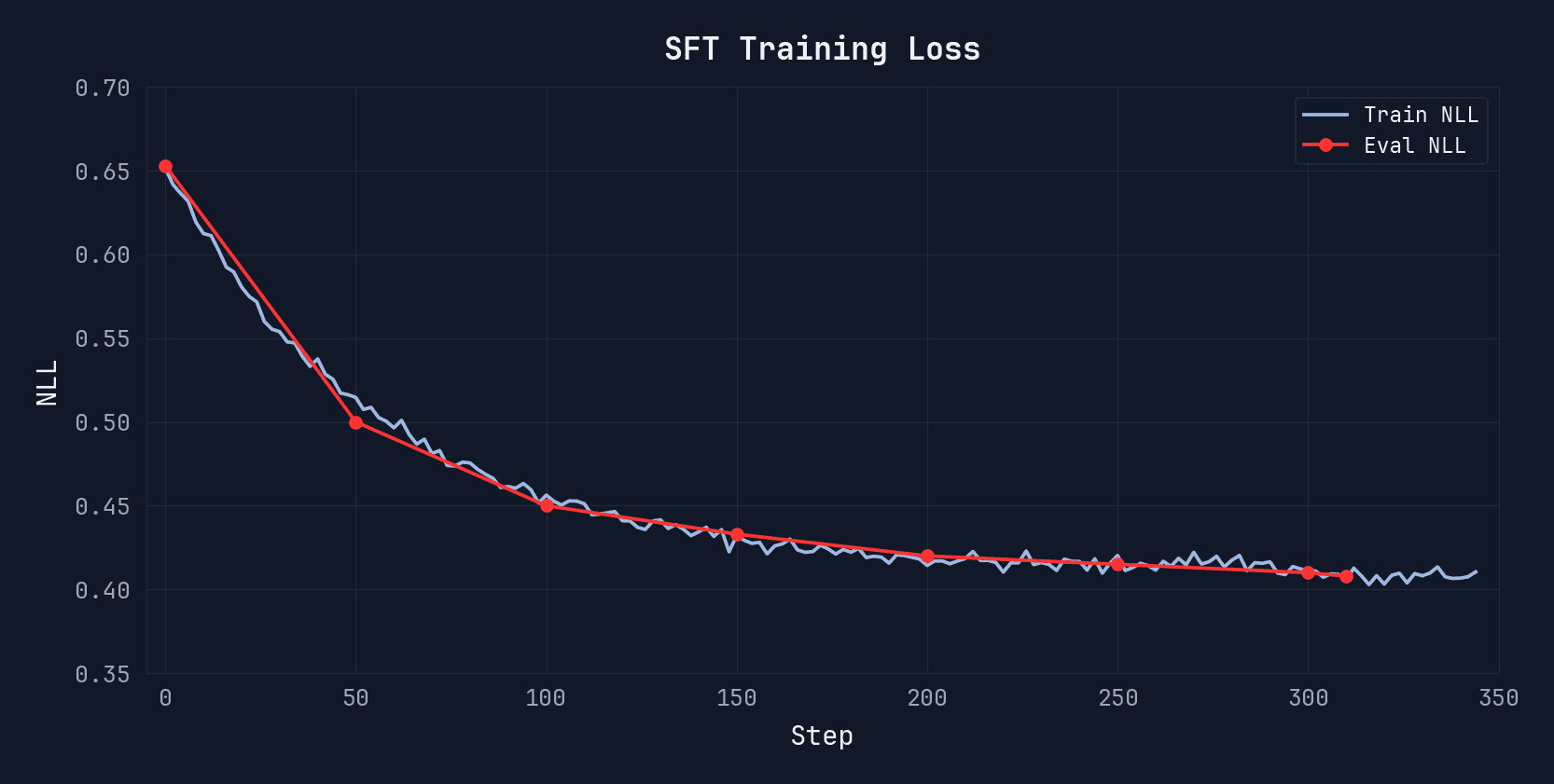
Eval NLL drops from 0.65 to 0.45 over ~300 steps. We pick the checkpoint before overfitting begins, where test NLL is still improving but the model hasn’t started memorizing specific conversations.
Stage 2: RLVR
The environment
We built a multi-turn RL environment using components from Harbor, the same framework used for official Terminal-Bench 2.0 evaluation. Each episode works like this:
Fresh Docker container spins up with the task environment.
Model interacts with the container via terminus-2.
Test suite runs. Results become the reward signal.
For speed, training episodes are capped at 20 turns with no context summarization. Our evals use terminus-2 defaults (no turn limit, summarization enabled, k=5).
Reward
The official Terminal-Bench 2.0 evaluation uses binary reward: a task either passes or fails. For RL on a model with low baseline capability, this reward is too sparse.
Instead, we use per-test reward: the fraction of individual tests that pass in each task’s test suite. If a task has 10 tests, a model attempt that passes 7 earns a reward of 0.7 rather than 0. This lets the RL algorithm distinguish between an attempt that passes 3/10 tests and one that passes 7/10, even though both would score 0 under binary grading.
Beyond the test reward, we also applied a function that incentivizes faster solutions, so when multiple successes occur within the same group, the more efficient solution is given priority.
Harbor loads task (instruction + Dockerfile + test.sh), boots container
Model receives task prompt + terminal state (root@container:/app#)
Agent loop (up to 20 turns): model outputs JSON → terminus-2 executes → terminal output back to model
Episode ends. test.sh runs inside the container.
Reward: per-test correctness (80% weight) + efficiency (20% weight)
RL Task Selection
Not all tasks are equally useful for RL. Tasks the model solves consistently or fails every time provide no learning signal. We select tasks where the SFT checkpoint has a 10–80% solve rate. These are the tasks where GRPO can compute meaningful advantages: some attempts succeed, some fail, and the model can learn from the difference.
0–10% solve rate
Never solves it. No positive signal.
10–80% solve rate
We train here. Wins and losses to learn from.
80–100% solve rate
Too easy. Nothing to learn.
Training
We configure GRPO with a group size of 16, generating 16 independent attempts at each task per training step. The model learns from the contrast between its own winning and losing trajectories on the same problem.
Launching the RLVR stage on Tinker:
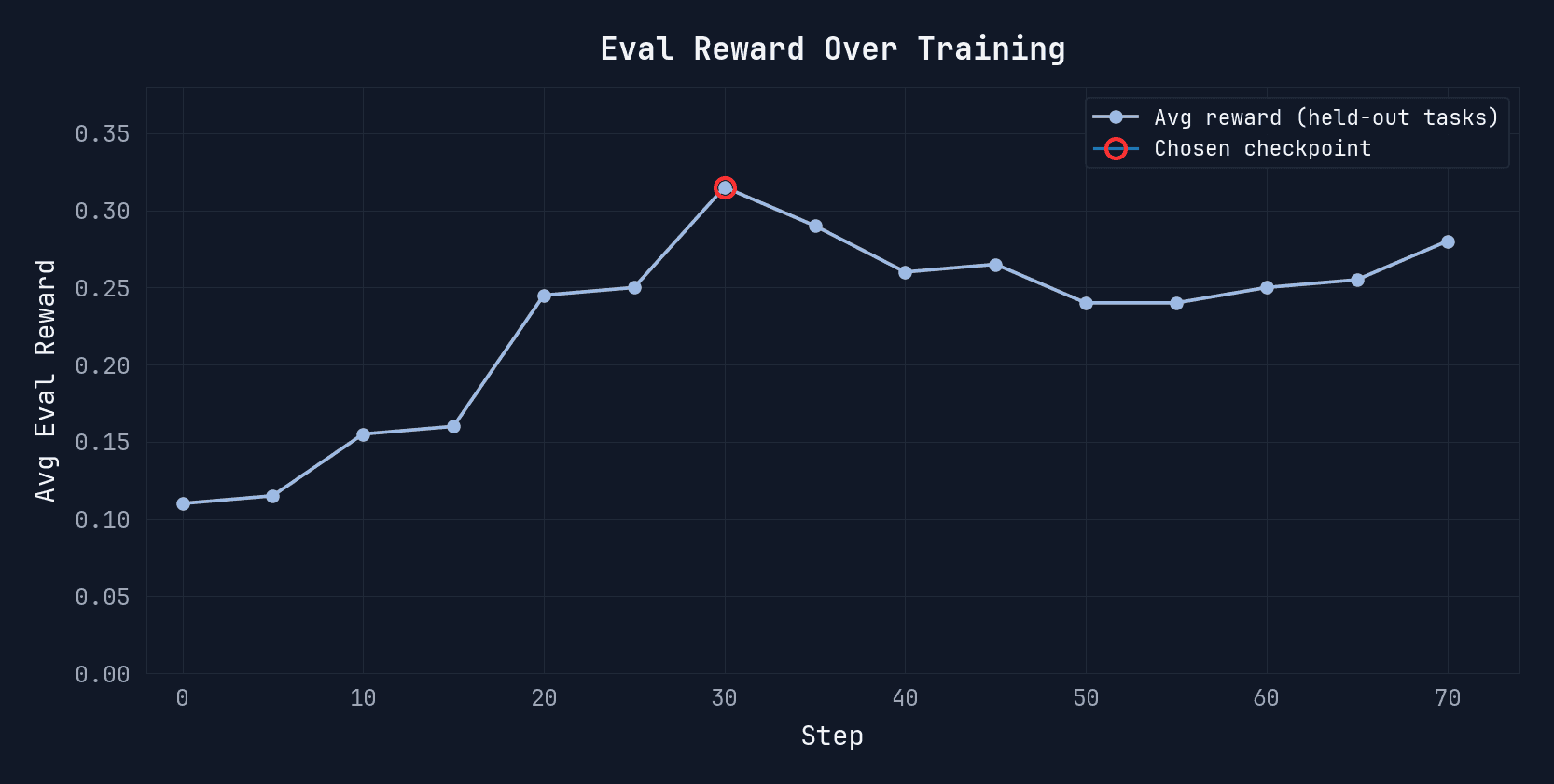
Eval reward climbs steadily over the first ~30 steps, then plateaus. We select the checkpoint at peak held-out reward before returns begin to diminish.
SFT only | 13.5% |
SFT + RLVR | 17.0% |
All RL training tasks were sourced from AfterQuery’s expert-labeled datasets, curated by AfterQuery’s network of software engineering experts.
Data is the lever
The largest gain in this pipeline comes from the SFT stage, which is entirely a function of data quality. The model learns from rollouts where real terminal environments were set up, explored, and solved end-to-end.
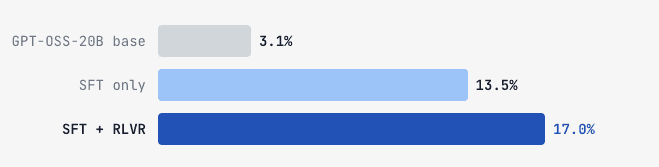
The RLVR stage improves performance by another 3.5%. But it only works because the SFT checkpoint is already capable enough to sometimes solve the training tasks, giving GRPO meaningful signals to amplify. SFT makes meaningful RL possible.
What the improvement looks like in practice
The base model jumps straight into writing code without checking the environment, guesses at tools, and hardcodes the answer when stuck.
Our model explores first, reads the source code, installs dependencies, then builds a working solution.
Results
Configuration | Agent | Pass Rate |
|---|---|---|
openai/gpt-oss-20b (base) | Terminus 2 | 3.1% |
AfterQuery | Terminus 2 | 17.0% |
Our trained model passes every task the base model passes, plus 18 more.
Discussion
Why Terminal-Bench 2.0
Terminal-Bench 2.0 tests whether an agent can actually operate in a real terminal environment: installing packages, debugging build failures, navigating filesystems, writing and running scripts. The tasks require multi-step reasoning in environments with real tools and real failure modes. Improving on it means improving the capabilities that matter for real-world agent deployment.
What changed after training
The most visible difference between the base model and our finetuned model is not raw coding ability — it’s workflow. The base model tends to start writing code immediately based on assumptions about the environment. Our model consistently begins by exploring: listing files, reading configs, checking installed tools. It builds a mental model of the environment before acting. When something fails, it reads the error and adapts rather than retrying the same approach.
This pattern — explore, then act — emerges consistently across tasks and was not explicitly rewarded. It appears to be a natural consequence of training on trajectories where that behavior leads to passing tests.
What didn’t work
Early in the project, we tried shaping first-turn behavior directly. The hypothesis was that if the model always starts by exploring the environment, downstream performance would improve. We implemented a reward signal that specifically incentivized information-gathering actions in the opening turn.
It didn’t help. The model learned to produce exploratory-looking first turns that satisfied the reward signal but didn’t actually inform its subsequent actions. The exploration was performative rather than functional. We removed the shaping reward, and the behavior we wanted emerged on its own once the model had enough signal from actually passing tests.
Get in touch here to access our off-the-shelf Terminal-Bench, SWE agent, and agentic post-training datasets, or reach out to us directly at research@afterquery.com.
AfterQuery is an applied research lab curating data solutions to accelerate foundation model development.
Evaluation on Terminal-Bench 2.0 (89 tasks), terminus-2 agent. Temperature 1.0, max output 4096, max context 32K. Pass@1 averaged over 5 runs.



