Blog
·
How AfterQuery Expert Data Drives Model Performance on τ²-bench

Michael E.

Spencer M.

Arya F.

| Header 1 | Header 2 | Header 3 |
|---|---|---|
| Cell 1-1 | Cell 1-2 | Cell 1-3 |
| Cell 2-1 | Cell 2-2 | Cell 2-3 |
Using just 1,057 rollouts from our off-the-shelf τ² dataset, AfterQuery researchers were able to improve Llama-3.1-8B-Instruct performance on the official τ² benchmark by up to 4.33× in some domains.
τ²-bench measures how well models operate as customer-service agents in dual-control scenarios, where success requires not just reasoning and tool use, but coordinating with a user who is actively modifying shared state.
The benchmark
τ²-bench simulates realistic customer-service interactions. Each domain defines an agent policy, a set of tools and APIs, a task suite, and a user simulator. The agent must navigate multi-turn conversations, call the right tools with the right arguments, and follow domain-specific policies, all while interacting with a simulated customer.
For example, in one official τ²-bench task a customer tries to cancel a flight reservation past the allowed window and pushes back when the refund is denied. The agent must hold firm and refuse the cancellation per airline policy.
Our data builds upon all 3 public τ² domains with new scenarios, and introduces 2 new domains built by AfterQuery:
Airline
Retail
Telecom
BankingAfterQuery
HealthcareAfterQuery
Our evaluation methodology used the test split for each domain where applicable (e.g. tau2-airline-splits): retail (40 tasks), telecom (40 tasks), airline (33 tasks). This differs from AA's methodology, which used all 114 tasks for telecom.
Training
We fine-tuned Llama-3.1-8B-Instruct on 1,057 rollouts from AfterQuery's off-the-shelf dataset, covering 500 unique tasks across 6 domain variants. Rollouts were filtered via rejection sampling to keep only passing trajectories. Every training sample was disjoint from both our validation set and the official τ² benchmark.
LoRA SFT Configuration
Parameter | Value |
|---|---|
Base Model | meta-llama/Meta-Llama-3.1-8B-Instruct |
Training Infrastructure | 8x H100 |
LoRA Rank | 32 |
Learning Rate | 2e-5 |
LR Schedule | Cosine |
Batch Size | 16 |
Epochs | 3 |
Max Sequence Length | 32,768 |
The full training run completed in under 20 minutes on 8x H100s. Training loss dropped by roughly 45%, with eval loss tracking closely and no significant overfitting, suggesting the model learned generalizable patterns rather than memorizing specific conversations.
Results
We evaluated each checkpoint against the unmodified base model. Both used gpt-4.1 as the user simulator, with temperature set to 0.0.
Retail saw the largest relative gain at 4.33x. Telecom improvement peaked early at step 60 then declined, as later checkpoints appeared to overfit away from telecom-specific patterns. Airline improved steadily through training.
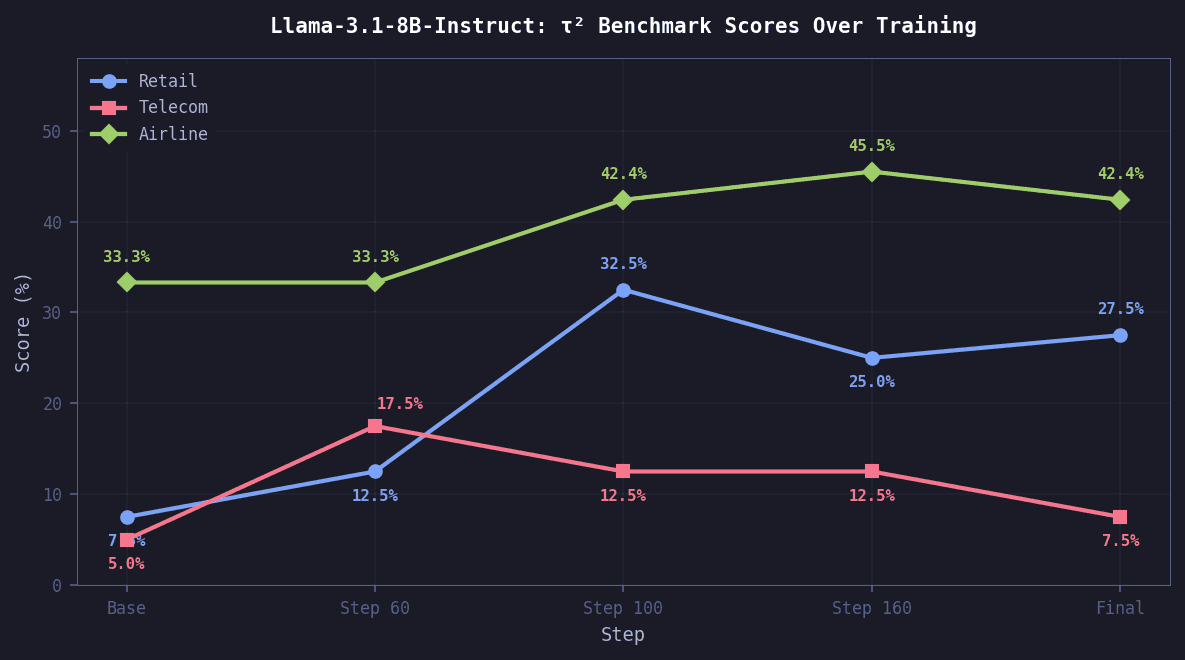
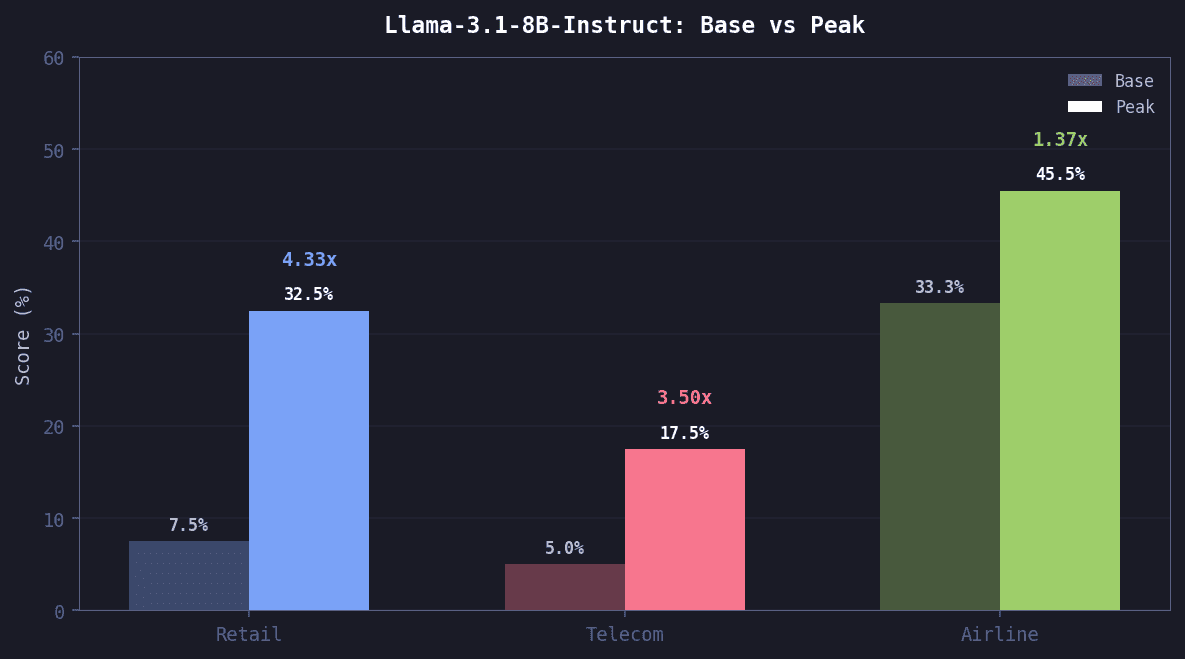
Evaluation setup
Our Checkpoints
terminal
Base Model
terminal
How model behavior changed
The most visible difference between the base model and our fine-tuned model is workflow, not raw capability. The base model tends to guess at tool arguments immediately, fabricating order IDs and placeholder emails. Our model consistently begins by asking the user for identifying information, then calls tools with real values.
Behavioral Metrics: Base vs SFT
Metric | Base | SFT |
|---|---|---|
Uses placeholder/fabricated tool arguments | 91% of tasks | 5% of tasks ▼ |
Asks user for identity before acting | 6% of tasks | 95% of tasks ▲ |
Avg tool calls per task | 8.6 | 8.0 |
Avg conversation length | 29 messages | 27 messages |
What the improvement looks like in practice
Retail, Task 17: A user wants to update the delivery address on a pending order but doesn't remember her email. The agent must verify her identity via name and zip code, look up the correct order across multiple results, and apply the address change.
Base model: passes, but stumbles first
SFT model: passes, clean workflow
Data is the lever
These results are driven primarily by data quality. Using only a small fraction of a single curated AfterQuery dataset, one SFT stage was enough to shift model behavior and generalize to unseen tasks. We believe adding RL via τ²'s gymnasium is a clear next step to push performance further.
Get in touch here to access our off-the-shelf τ² and agentic post-training datasets, or reach out to us directly at research@afterquery.com.
AfterQuery is an applied research lab curating data solutions to accelerate foundation model development.
Evaluation on τ² benchmark test splits. Retail: 40 tasks, Telecom: 40 tasks, Airline: 33 tasks. User simulator: gpt-4.1. Temperature 0.0 for both agent and user. Single trial.




