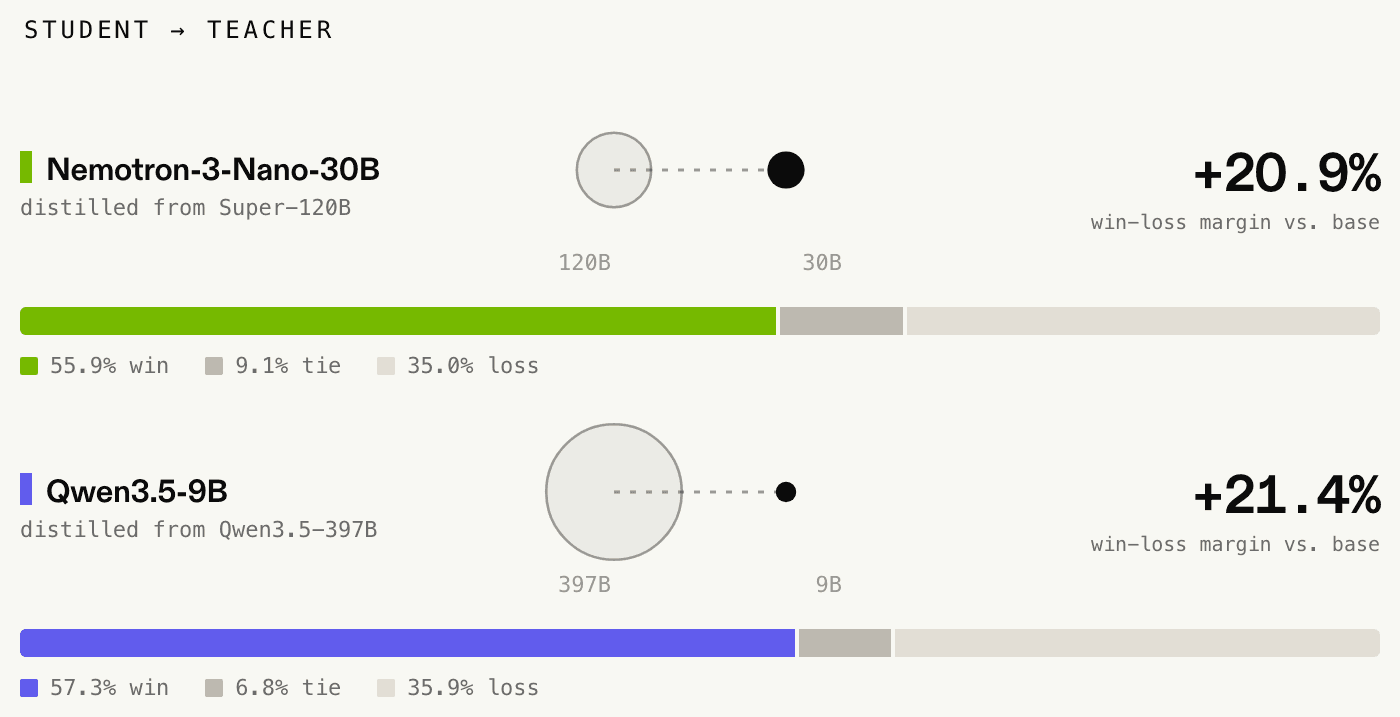
How we achieved a net win-loss margin of +21.4% on GDPval with on-policy distillation
 Michael E.
Michael E. Spencer M.
Spencer M.AfterQuery researchers trained NVIDIA’s Nemotron-3-Nano-30B-A3B with on-policy reverse-KL distillation from a frozen Nemotron-3-Super-120B-A12B teacher, using Tinker. We then evaluated the result on GDPval, OpenAI’s benchmark for professional knowledge-work tasks. After only 50 steps of training, the Nemotron student’s mean GDPval rubric score increased by 5.1 points, yielding a +20.9% net win-loss margin against the base model. The training split contained only tasks from AfterQuery’s Off-The-Shelf Office Agent Training Dataset and no examples from the public GDPval eval set.
We then reproduced the result with a different model family. The same recipe applied to Qwen3.5-9B, distilled from a Qwen3.5-397B-A17B teacher, produced a comparable +21.4% net win-loss margin against the base model.
What is on-policy distillation?
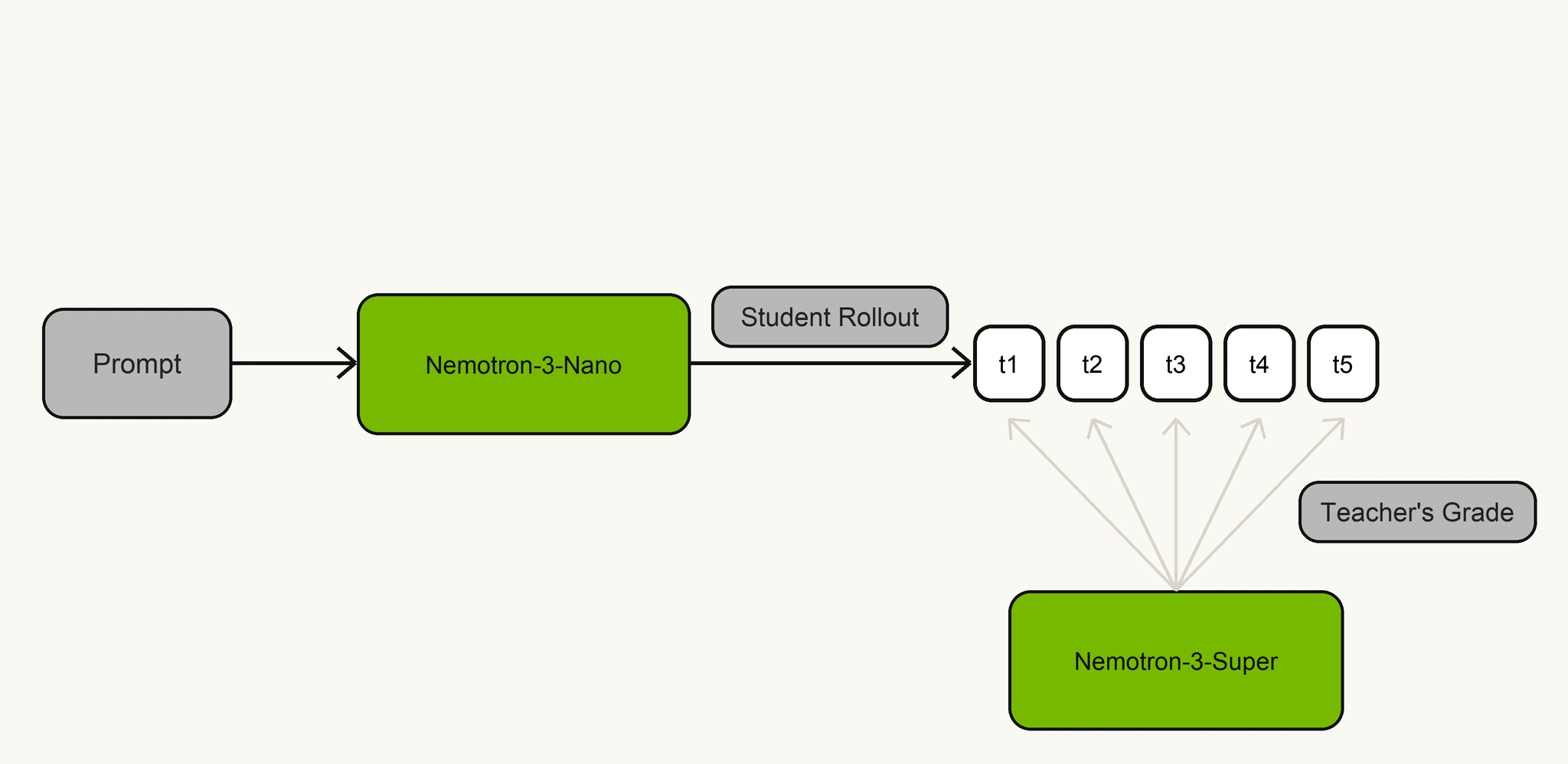
In on-policy distillation, a student model learns by comparing its own generations against those of a stronger teacher.
For each task, the student samples a rollout token by token. For every token the student produced, the teacher asks how likely it would have been to produce that same token, given everything that came before it. Ordinary off-policy distillation trains the student on excellent rollouts it would never produce on its own; on-policy distillation trains it on the messy ones it actually generates. You can think of it like the difference between memorizing flashcards of correct answers and having a tutor grade your own homework: the flashcards only ever show the right answer, while the tutor catches the exact step where you went wrong. This matters especially for the GDPval benchmark, where an intermediate mistake tends to corrupt every action that follows. An agent that opens the wrong file or starts from a wrong assumption must then recover from the resulting situation.
The signal is a per-token reverse KL in the student-to-teacher direction.¹
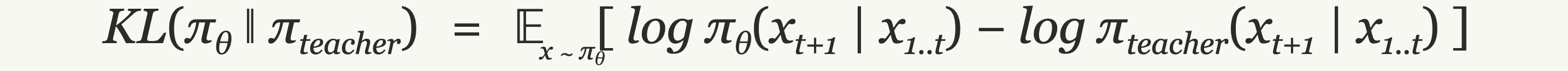
Each term is the student’s log-probability for a sampled token minus the teacher’s for the same token. Minimizing it pushes the student toward tokens the teacher finds more likely and away from tokens it finds less likely.
Configuration
In our experiment, we used Nemotron-3-Super as the teacher because it is substantially stronger than Nano while staying in the same model family, and Nemotron-3-Nano as the student because it starts from a much lower professional-work baseline, as reflected on the public GDPval-AA leaderboard. Keeping both in the same family helps since they share a common tokenizer, chat template, and response style. As a result, less of training is spent correcting format mismatches. The loop follows the Tinker recipe for on-policy distillation. Nano samples the task rollout. Super is queried for log-probabilities on Nano’s sampled tokens. Tinker turns the log-probability difference into a negative reverse-KL token signal, then updates only the Nano LoRA adapter through its importance-sampling loss.
Training configuration
| Setting | Value |
|---|---|
| Student | nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 |
| Teacher | nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 |
| Renderer / chat template | nemotron3 |
| Loss | importance_sampling with per-token reverse KL |
| Dataset size | 800 AfterQuery OTS Professional-Work Tasks |
| KL coefficient | 1 on teacher KL |
| Learning rate | 1e-4 |
| LoRA rank | 32 |
| Batch size | 16 |
| Temperature | 1 |
Results
Training curves
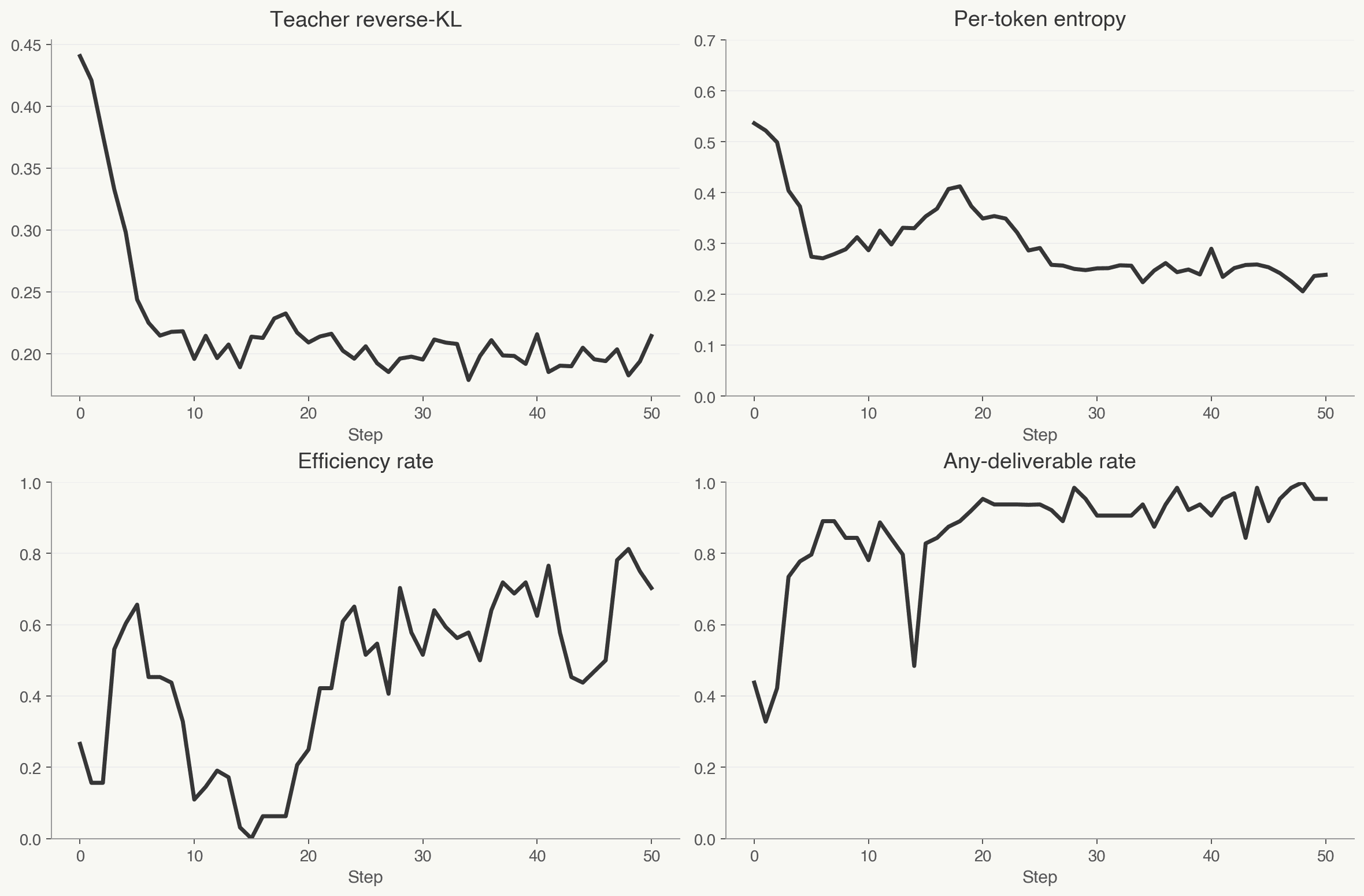
As Nano’s token distribution moves toward Super’s, its per-token entropy falls and the model grows more decisive: it produces a usable deliverable more often, and does so more efficiently.
Improvement on the official GDPval eval
After only 50 steps of training, our distilled model improves on both aggregate scoring and paired comparisons across all 220 tasks in OpenAI’s official GDPval eval set. Mean weighted rubric score is up 5.1 points, and the distilled model wins 123 of the 220 task pairs, ties 20, and loses 77 — a 55.9% win rate and a +20.9% net win-loss margin against the base model. A two-sided sign test on the decisive task pairs confirms the margin is statistically significant (p ≈ 0.001).
Is this specific to Nemotron, or is on-policy distillation a general lever for professional work? We ran the identical recipe on a completely different family to find out: Qwen3.5-9B as the student, distilled from the far larger Qwen3.5-397B-A17B teacher. Same on-policy reverse-KL signal, the same Tinker recipe, the same AfterQuery Off-The-Shelf GDPval Training Dataset. The gain carried over, and was if anything larger. The distilled Qwen student improved its mean weighted rubric score by 7.9 points over the base model, achieving a 57.3% win rate and a +21.4% net win–loss margin.
What improvement looks like in practice
Below, the base model’s deliverable beside the distilled model’s on the same task, for both model families. Use the arrows to page through each file.
Example #1
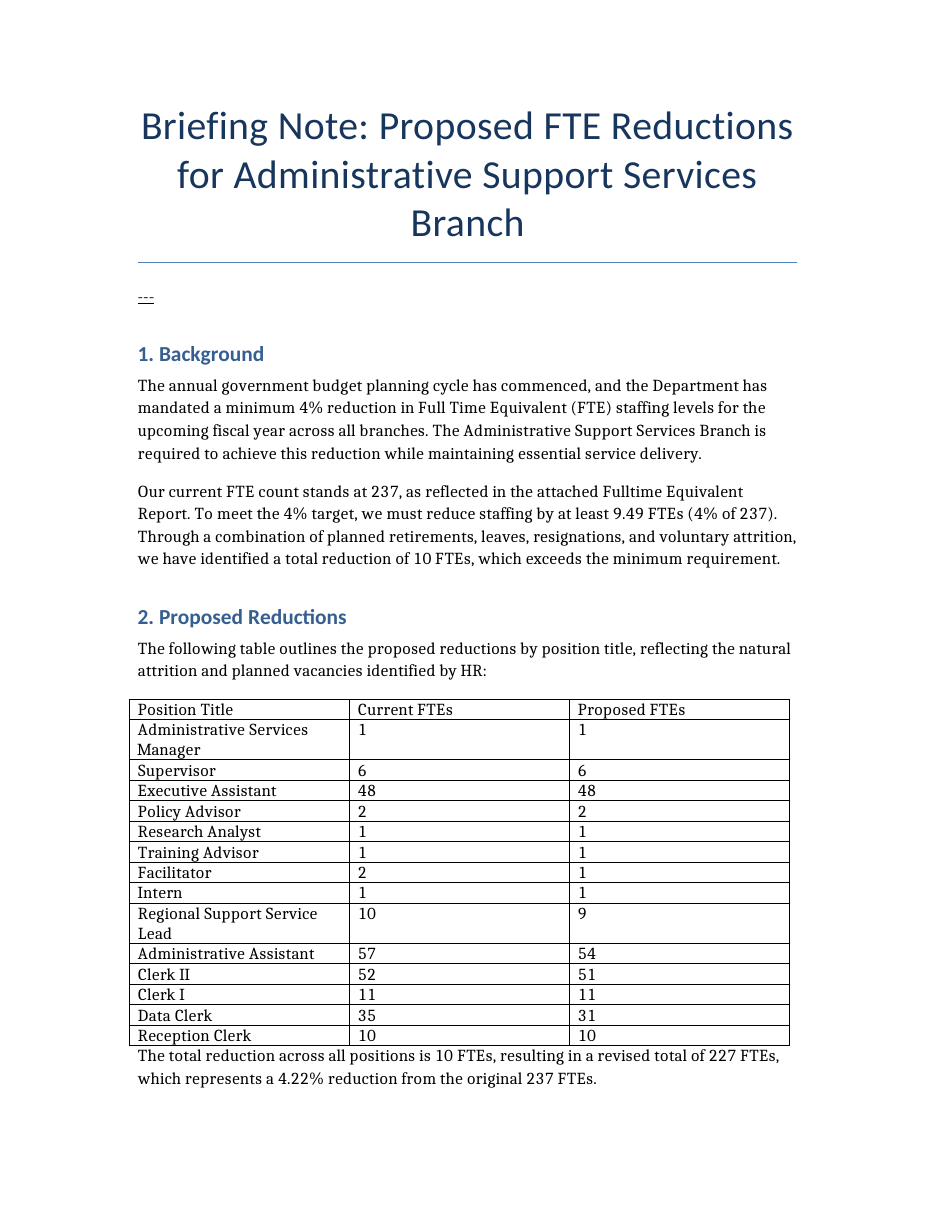
Nemotron-3-Nano — Task c44e9b62 asks for a briefing note, FTE spreadsheet, and revised org chart for a government staffing plan.
Task excerpt. “Create an information package on FTE reductions for your branch. The package should include a revised organizational chart as a PDF, an updated FTE report in Excel, and a briefing note describing the background, proposed reductions, and fit with budget planning principles.”







Qualitative patterns
- Substance over scaffolding. Base outputs often had the right shell with placeholders. Distilled outputs more often filled sections with specific policy text, analysis, rows, and supporting details.
- Artifacts that actually work. The distilled model builds artifacts that actually function: Excel sheets that use live formulas instead of hard-coded values, working tables and cross-references, and document structure that holds together rather than breaking under its own formatting.
- Follows the formatting it’s told to. Tasks showcase stronger instruction following, specifically with formatting-related requests like highlights, date blocks, and signature blocks.
- Expert depth, not surface answers. The distilled model goes a level deeper, giving the specific details an expert would rather than a surface answer. In the hypertension literature review above (Example #4), the distilled model engages the clinical specifics the task calls for, like prevalence across older age groups, the morbidity and mortality tied to poor adherence, and the financial impact, where the base model stays general.
Measuring the shift outside the targeted capability
When a model is pushed hard on one kind of work, it often loses ground on everything else. Rather than measuring generalization across many benchmarks that target the same capability, we looked for regressions on work the model never practiced. We compared the distilled Nemotron model with the base on graduate-level reasoning, broad knowledge, competition math, and code. The scores hold. Across GPQA, MMLU-Pro, AIME, LiveCodeBench, and SciCode, every score stays within run-to-run noise of the published base. The GDPval improvement did not come at the expense of general ability.
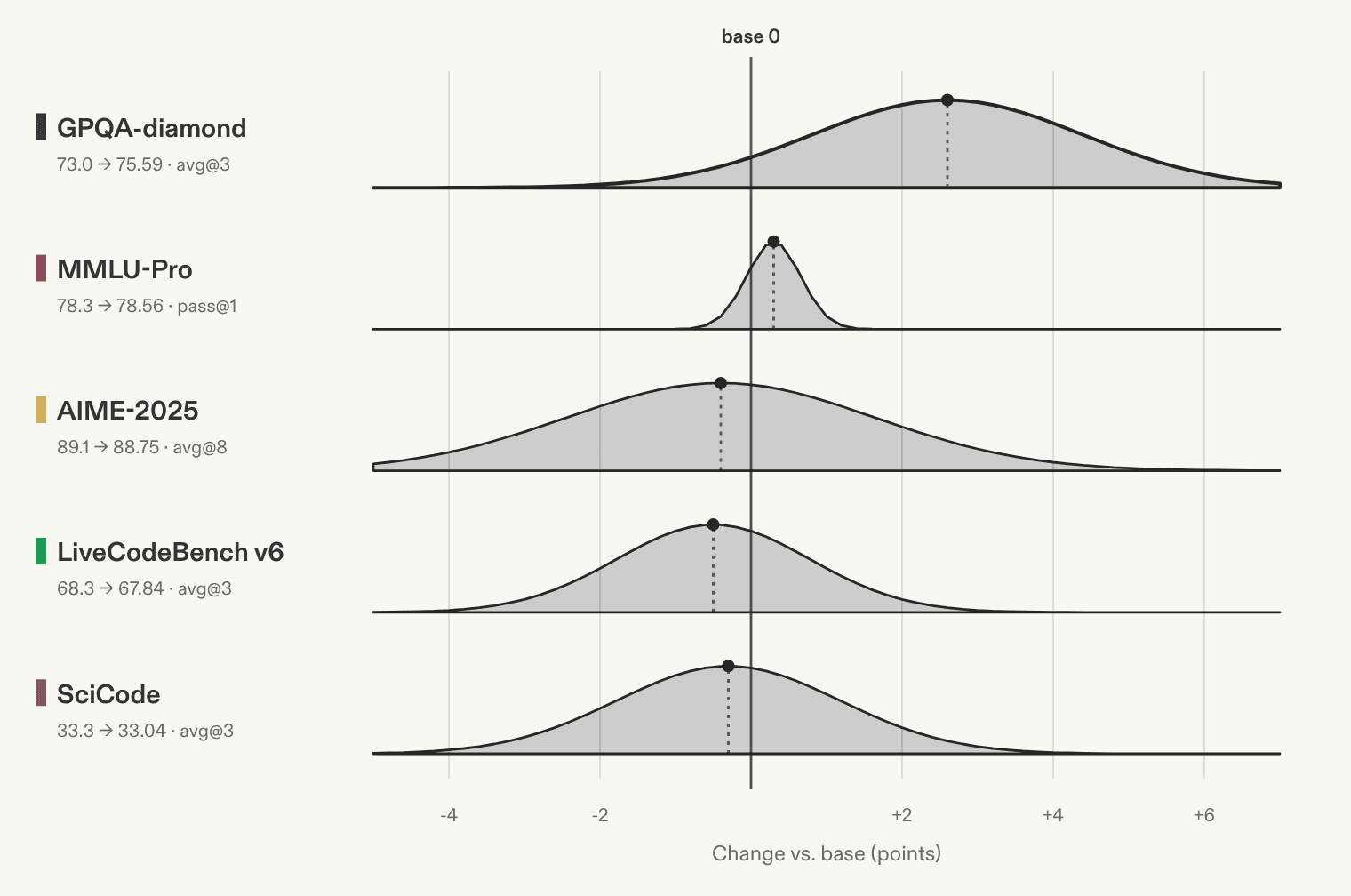
Baseline results are NVIDIA’s published Nemotron-3 Nano numbers, produced with NVIDIA’s NeMo Evaluator. The distilled results are our 50-step checkpoint, evaluated with NeMo Evaluator and NeMo Skills under the sampling parameters from NVIDIA’s official evaluation config.
Human data as a lever
The mechanism improving Nano is the distillation process, but it only works so well because the student is practicing on tasks that mimic real work. Our gains in performance were only possible because the AfterQuery Off-The-Shelf Office Agent Training Dataset used well-seeded workspaces, messy inputs, specific deliverables, and realistic constraints, like the structure seen in the official GDPval eval.
This same AfterQuery data was used by NVIDIA in the development of Nemotron 3 Ultra to hillclimb GDPval, as cited in their technical report.
Our evaluation harness
AfterQuery’s GDPval evaluation harness follows the same broad shape as Artificial Analysis’s GDPval-AA methodology, which is built on OpenAI’s original GDPval benchmark. It runs in two stages.
The execution stage is built directly on Stirrup, the open-source agent framework Artificial Analysis developed and used for GDPval-AA. Stirrup runs a minimal Reason-Act-Observe loop, gives the model a small set of tools, and lets the model choose its own approach. The tools include shell and code execution, web search, web fetch, image viewing, and a finish tool.
The grading stage is where our setup differs. Artificial Analysis uses Gemini 3.1 Pro for pairwise comparisons between anonymized model submissions, then turns those comparisons into an Elo-style ranking. We grade responses directly against OpenAI’s public GDPval rubrics from the Hugging Face release. Three Gemini 3.1 Pro graders independently mark each criterion, and majority vote gives the final weighted score.
Get in touch here to access our off-the-shelf GDPval, Office Agent, and agentic post-training datasets, or reach out to us directly at research@afterquery.com.
AfterQuery is an applied research lab curating data solutions to accelerate foundation model development.
References
- Lu, Kevin, and Thinking Machines Lab. On-Policy Distillation. Thinking Machines Lab: Connectionism, Oct. 2025. thinkingmachines.ai/blog/on-policy-distillation. doi:10.64434/tml.20251026.
- Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Ramos, S., Geist, M., Bachem, O. On-Policy Distillation of Language Models, Learning from Self-Generated Mistakes. ICLR 2024. The modern reference for on-policy distillation of language models; introduces the Generalized Knowledge Distillation (GKD) framework. arxiv.org/abs/2306.13649
- Ross, S., Gordon, G. & Bagnell, J. A. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. AISTATS 2011. The DAgger paper, origin of the on-policy framing as a way to avoid the exposure-bias failure mode of pure behavior cloning. arxiv.org/abs/1011.0686
- Minka, T. Divergence measures and message passing. Microsoft Research Technical Report MSR-TR-2005-173. The canonical reference for the mode-seeking behavior of reverse-KL vs. the mode-covering behavior of forward-KL. microsoft.com/en-us/research/publication/divergence-measures-and-message-passing
- NVIDIA. NVIDIA Nemotron 3, Efficient and Open Intelligence (white paper, arXiv 2512.20856); and Nemotron 3 Nano, Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning (arXiv 2512.20848). Model cards are Nemotron-3-Nano-30B-A3B (HF) and Nemotron-3-Super-120B-A12B (HF).
- OpenAI. GDPval, an economically-grounded agent benchmark. openai.com/index/gdpval · dataset (HF)
- Artificial Analysis. Intelligence benchmarking methodology. artificialanalysis.ai/methodology/intelligence-benchmarking